Pytorch Lightning을 활용한 AMP 사용방법에 대해 다룹니다.
1. Introduction
GPT-3의 등장처럼 최근 딥러닝 모델의 발전방향성은 파라미터 수를 극강으로 키우는 쪽으로 나아가고 있습니다. 그렇다면 반대급부로 당연히 연구가 활발해지는 주제는 “어떻게 하면 모델의 크기를 줄일까”입니다. 이 주제는 Network Compression이며 다음과 같이 4가지 정도의 접근방법을 가지고 있습니다.
- Low Precision Training
: 정확도의 손실이 있더라도 모델의 precision 낮추어 학습하는 방법
- Quantization
: 모델 학습 후 파라미터의 타입을 압축하는 방법
- Pruning
: 모델 학습 후 불필요한 connection들을 가지치기 하는 방법
- Dedicated Architecture
: memory-efficient하게 설계된 네트워크를 구성하는 방법
이 중에서도 Mixed Precision은 1번 방식에 속하며 최근 Pytorch 1.6에 기본적으로 내장되었습니다. 이에 대한 상세한 내용은 Nvidia Blog 에서 확인할 수 있으며, 이 글에서는 직접 Pytorch 1.6을 활용해 Mixed Precision을 적용하는 방법에 대해 다뤄보도록 하겠습니다.
기존에 Pytorch를 활용한 AMP (Automatic Mixed Precision)을 활용하기 위해선 Nvidia에서 개발한 Apex를 활용해야 했습니다. 그렇지만 이제 Pytorch에 AMP가 공식적으로 통합되며 이제 Apex의 개발이 중단된다고 합니다.
이렇게 Pytorch 1.6+에 적용된 native AMP 사용법은 코그닉스의 호성님이 이렇게 잘 정리해주셔서 굳이 다시 정리할 필요는 없을듯하여, 최근 Pytorch Wrapper 로 떠오르고 있는 Pytorch Lightning을 활용하여 AMP를 사용하는 법에 대해 정리해보려고 합니다.
2. 사용방법
기본적인 Pytorch Lightning 설치법은 링크를 참고해주세요.
호성님의 자료를 보시면 Pytorch native amp의 사용방법도 매우 간단한 걸 보실 수 있지만, Pytorch Lightning을 활용하면 더욱 간단하게 사용할 수 있습니다.
사실상 다른 코드들은 그대로 유지한채, Trainer에 다음과 같은 파라미터들을 넘겨주면 되는데요.
1 | |
amp_backend 는 디폴트 값이 native라 사실 넘겨주지 않아도 되는 파라미터이며 precision 을 32가 아닌 16으로 넘겨주게 되면 amp가 적용되게 됩니다. 만약 Pytorch 1.6+버전을 사용하고 있지 않아서 Apex의 AMP를 활용해야하는 경우에는 amp_backend='apex' 로 변경해주시면 됩니다.
3. Benchmark
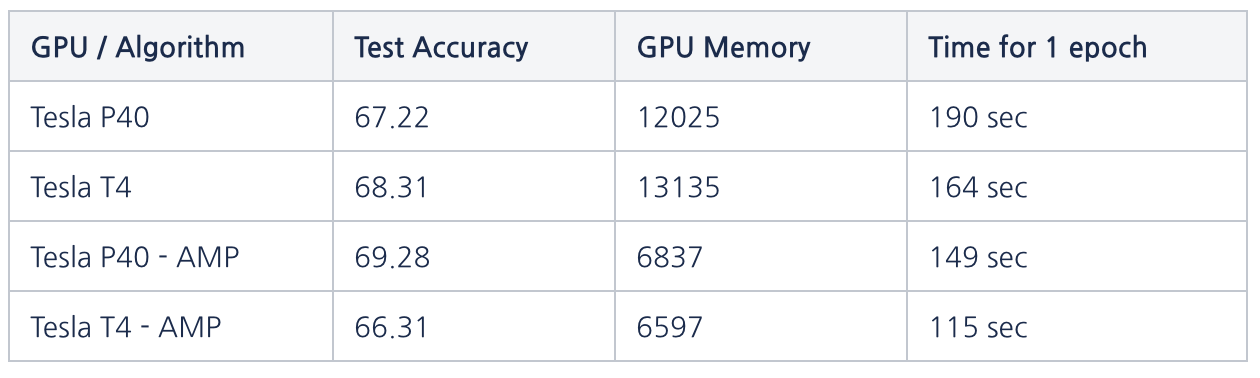
그럼 어느정도의 학습속도/메모리사용량에 gain이 있는지 간단한 벤치마크를 돌려봤는데요. 벤치마크 스펙은 다음과 같습니다.
1 | |
4. 결론
사실상 거의 performance down이 없으면서 GPU메모리 점유는 약 절반, 학습속도도 T4의 경우 30%, P40의 경우 23%가량 좋아지는 것을 확인할 수 있습니다.
많은 경우에 Free Launch는 없다고들하지만, Pytorch AMP같은 경우에는 오히려 안쓸이유가 전혀 없는 접근으로 보입니다. 더군다나 사용법자체도 매우 간단하구요.
결론: 열심히 씁시다.
추가로 확인해봐야할 것 같은 부분은 T4는 TensorCore를 지원해서 더 빠르다는데 지원하지 않는 P40에 비해 성능 gain이 크지는 않은 것 같아 조금 더 깊이 파봐야할듯 합니다. 이 부분도 완료되는대로 포스팅해두겠습니다.