안녕하세요.
Fastai v2가 최근에 릴리즈되었기에 간단한 이미지분류문제 튜토리얼을 진행해보고자 합니다.
Fastai v2에 대한 내용을 보시려면 이 링크를 참고해주세요.
1. Fastai v2 설치하기
현재 fastai v2를 설치하려면 pytorch==1.6.0 / torchvision==0.7.0가 필요합니다. 해당 버전들은 기본적으로 CUDA 10.2에 맞춰져있기에 만약 여러분의 컴퓨터에 CUDA 10.1이 설치되어 있다면 GPU를 제대로 활용할 수 없습니다. (물론 Multi-CUDA 버전 시 문제없음)
그런 경우에는 아래와 같이 pytorch와 torchvision을 CUDA 10.1 빌드버전으로 먼저 설치 뒤 fastai를 설치하면 됩니다. (해당사항 없으신 분들은 단순히 fastai 설치만 진행하시면 됩니다.)
1 | |
2. Fastai v2 시작하기
2.1. 샘플데이터 다운받기
보통 이미지분류문제의 hello, world!는 MNIST이지만 이번에는 개/고양이 분류문제를 한번 다뤄보겠습니다.
1 | |
먼저 위의 코드를 보시면서 왜 저렇게 짜? import * 를 쓰는 것은 권장되지 않는다고 배웠는데.. 하시는 분들이 있으실텐데요. 해당 내용은 반은 맞고 반은 틀렸습니다. 보통 import * 를 안쓰는 이유는 해당 모듈과 관련된 모든 모듈을 다 임포트해와서 권장하지 않는 것인데요. fastai v2에서는 제레미가 필요한 모듈만 불러올 수 있도록 처리해두었기 때문에 오히려 다음과 같이 import *를 통해 모든 메소드들을 손쉽게 쓰도록 권장합니다.
untar_data 메서드는 데이터를 다운로드하고 언팩하는 과정까지 포함하고 있는 메서드입니다. 그리고 해당 과정이 완료되면 데이터가 어디에 존재하는지 리턴해주므로 path는 데이터가 저장된 위치를 담고 있습니다.
마지막으로 path.ls() 를 통해서 해당 위치에 있는 데이터들을 확인할 수 있는데요. 리턴된 데이터위치는 기본적으로 파이썬의 Path객체인데 fastai에서는 그를 한번 더 감싸 몇 가지 편리한 메서드들을 추가해두었습니다. 그래서 .ls() 와 같은 형태로 해당 위치에 있는 데이터조회가 가능합니다.
이제 우리는 path/'images' 에 우리가 분류하고 싶은 데이터들이 있다는 것을 알 수 있습니다.
2.2. 데이터로더 구성하기
이제 학습을 위해 ImageDataLoaders 를 구성해보겠습니다.
1 | |
get_image_files 라는 handy function으로 손쉽게 파일들을 담은 리스트를 만들 수 있습니다.
label_func 같은 경우에는 파일이름에 있는 특정 규칙을 통해 레이블을 생성하는 함수입니다. fastai의 ImageDataLoaders.from_name_func 를 활용하면 이렇게 label_func를 넘겨주어 손쉽게 규칙을 통한 레이블링도 진행할 수 있습니다. fastai 개/고양이 데이터셋은 고양이 이름은 대문자로 시작하고, 개 이름은 소문자로 시작합니다. 그래서 개의 레이블은 False, 고양이의 레이블은 True가 되게 됩니다.
item_tfms 에 이미지를 어떻게 변환할 것인지 (여기서는 Resize(224))를 함께 넘겨줄 수 있습니다.
그럼 이제 구성한 이미지들을 한번 살펴볼까요? 이 경우에도 나이브 pytorch에서 matplotlib, seaborn 등을 통해서 뿌려야했던 것을 show_batch 메서드 하나만으로 뿌릴 수 있습니다.

3. 모델구성/학습
기본적으로 fastai는 learner라는 개념을 가지고 있습니다. 이미지분류 같은 경우에는 cnn_learner , unet_learner 가 있습니다. 지금 우리는 cnn_learner 를 사용해서 pretrained-resnet34를 활용해보겠습니다.
1 | |
이렇게 작성하면 손쉽게 pretrained-resnet34를 가져올 수 있습니다.
이제 학습을 진행해보겠습니다.
1 | |
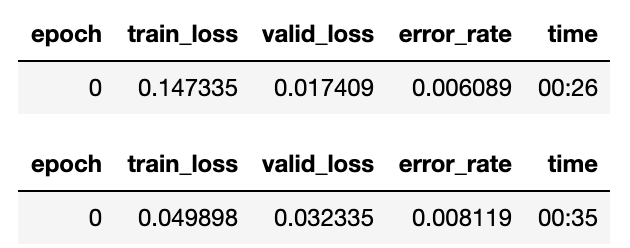
갑자기 한줄 쓰니 모델불러왔다고 하고 또 한줄쓰니 학습까지 완료되니 뭐 이것만 가지고 돼? 무슨 뜻이야? 싶으실텐데요.
먼저 fine_tune 메서드 같은 경우에는 freeze → one_cycle → unfreeze → one_cycle 를 한번에 진행해줍니다. freeze는 각 레이어의 trainable을 False로 바꾸는 작업이며, fastai의 fine_tune메서드에서는 freeze_to(-1) 가 기본값입니다. 그래서 마지막 그룹인 classifier를 빼놓고 앞단의 레이어들을 trainable=False로 만드는 것입니다.
그런데 아마 조금 더 궁금하신 분들은 다음과 같이 정말 freeze를 통해 trainable=False로 잘 바뀌는지 확인해보셨을텐데요.
1 | |
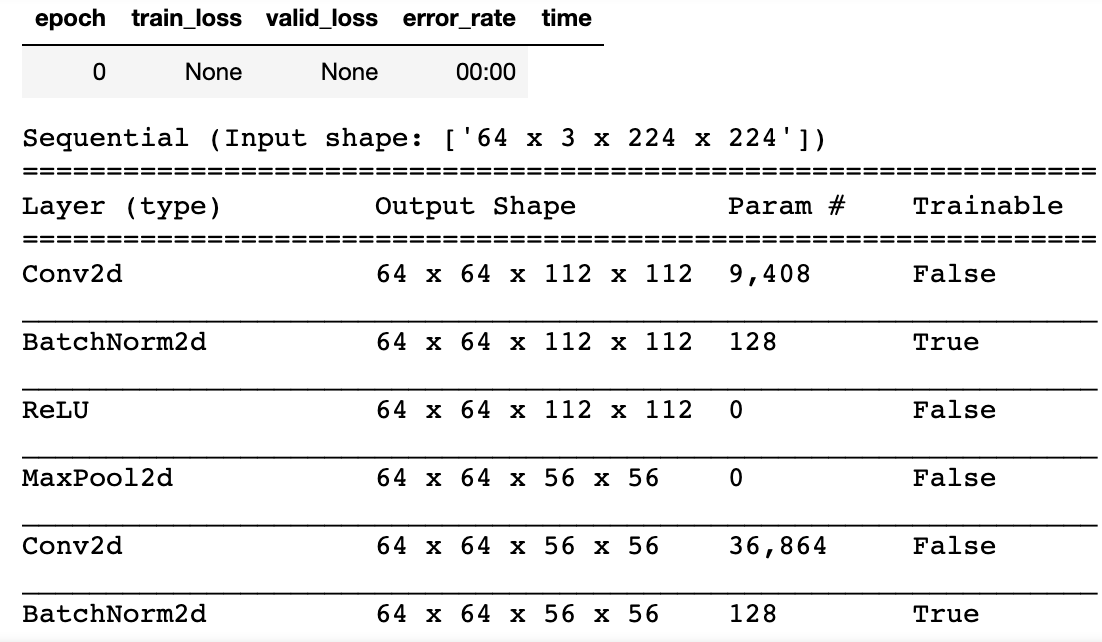
그런데 무언가 이상한 점을 발견하셨을 겁니다. 바로 BatchNorm레이어는 여전히 trainable=True인 것인데요. 이렇게 구현된 이유에 대해서는 다음 포럼에 설명되어 있으니 참고해주세요.
학습은 잘 되는 것을 확인했으니 예측이 잘 되는지 한번 테스트해볼까요?
1 | |

다음과 같이 강아지를 강아지라고 잘 예측하는 것을 볼 수 있습니다. 참고로 vocab을 콜해보면 다음과 같이 어떤 인덱스가 어떤 레이블을 뜻하는지 알 수 있습니다.
꼭 이런 방식이 아니더라도 다음과 같은 메서드를 활용해 결과를 볼 수도 있습니다.
1 | |

위의 True/False가 정답, 아래의 True/False가 예측값이라고 보시면 되고, 그 둘이 일치할경우 그린으로 나타납니다.
4. 마무리
이미 정제된 데이터에 이미 학습된 모델을 가져왔기에 큰 어려움 없이 튜토리얼을 따라하셨을 텐데요. 사실 이게 fastai의 가장 큰 장점이라고 생각합니다. 데이터 부분만 여러분들이 실제로 풀어야하는 문제데이터로 갈아치면 그 뒷 부분은 사실상 동일한 흐름으로 진행됩니다.
물론 이런 접근에는 장단점이 있습니다. 실제 이 fastai를 정말 자유롭게 모델링을 하고싶은 분이 쓰신다고하면 물론 불편함이 있을 수 있습니다. 저도 개인적으로 여전히 Pytorch 자체로 모델링을 하는 것을 더 편하게 느끼고 있구요.
다만, 최근 들어서 빠른 프로토타이핑에 대한 니즈가 커지다보니 프로토타이핑용 프레임워크/래퍼와 실제 딥한 연구용 프레임워크를 분리하는 것도 괜찮다는 생각을 하고 있습니다. 그래서 언제 마음이 바뀔지는 모르겠지만 당분간은 fastaiv2를 프로토타이핑용, pytorch 딥한 연구용, tensorflow를 배포용으로 활용해볼까 합니다.
사실 툴은 본인이 얼마나 능숙하게 다룰 수 있냐에 크게 좌우되는 것 같아 각자가 가장 편한 쉽게 다룰 수 있는 형태로 구성하시면 좋을 것 같습니다.
그럼 다음에는 좀 더 advanced한 내용으로 돌아오겠습니다.